
Operating system
An Operating System (OS)
is an interface between a computer user and computer hardware. An operating
system is a software which performs all the basic tasks like file management,
memory management, process management, handling input and output, and controlling
peripheral devices such as disk drives and printers.
Some popular Operating
Systems include Linux, Windows, OS X, VMS, OS/400, AIX, z/OS, Android, symbian
etc.
Definition
An operating system is a
program that acts as an interface between the user and the computer hardware
and controls the execution of all kinds of programs.

·
Memory Management
·
Processor Management
·
Device Management
·
File Management
·
Security
·
Control over system
performance
·
Job accounting
·
Error detecting aids
·
Coordination between
other software and users
Memory Management
Memory management refers
to management of Primary Memory or Main Memory. Main memory is a large array of
words or bytes where each word or byte has its own address.
Processor Management
In multiprogramming
environment, the OS decides which process gets the processor when and for how
much time. This function is called process scheduling.
Device Management
An Operating System
manages device communication via their respective drivers.
File Management
A file system is
normally organized into directories for easy navigation and usage. These
directories may contain files and other directions.
Types of Operating Systems
Following are some of the most widely used types of
Operating system.
1.
Simple Batch System
2.
Multiprogramming Batch System
3.
Multiprocessor System
4.
Distributed Operating System
5.
Realtime Operating System
SIMPLE
BATCH SYSTEMS
·
In this type of system, there is no direct interaction between
user and the computer.
·
The user has to submit a job (written on cards or tape) to a
computer operator.
·
Then computer operator places a batch of several jobs on an input
device.
·
Jobs are batched together by type of languages and requirement.
·
Then a special program, the monitor, manages the execution of each
program in the batch.
·
The monitor is always in the main memory and available for
execution.
Following are some disadvantages of this type of system :
1.
Zero interaction between user and computer.
2.
No mechanism to prioritize processes.
MULTIPROGRAMMING
BATCH SYSTEMS
·
In this the operating system, picks and begins to execute one job
from memory.
·
Once this job needs an I/O operation operating system switches to
another job (CPU and OS always busy).
·
Jobs in the memory are always less than the number of jobs on
disk(Job Pool).
·
If several jobs are ready to run at the same time, then system
chooses which one to run (CPU Scheduling).
·
In Non-multiprogrammed system, there are moments when CPU sits
idle and does not do any work.
·
In Multiprogramming system, CPU will never be idle and keeps on
processing.
Time-sharing operating systems
Time-sharing
is a technique which enables many people, located at various terminals, to use
a particular computer system at the same time. Time-sharing or multitasking is
a logical extension of multiprogramming. Processor's time which is shared among
multiple users simultaneously is termed as time-sharing.
MULTIPROCESSOR
SYSTEMS
A multiprocessor system consists of several processors that
share a common physical memory. Multiprocessor system provides higher computing
power and speed. In multiprocessor system all processors operate under single
operating system. Multiplicity of the processors and how they do act together
are transparent to the others.
Following are some advantages of this type of system.
1.
Enhanced performance
2.
Execution of several tasks by different processors concurrently,
increases the system's throughput without speeding up the execution of a single
task.
3.
If possible, system divides task into many subtasks and then these
subtasks can be executed in parallel in different processors. Thereby speeding
up the execution of single tasks.
DISTRIBUTED
OPERATING SYSTEMS
The motivation behind developing distributed operating
systems is the availability of powerful and inexpensive microprocessors and
advances in communication technology.
These advancements in technology have made it possible to
design and develop distributed systems comprising of many computers that are
inter connected by communication networks. The main benefit of distributed
systems is its low price/performance ratio.
Following are some advantages of this type of system.
1.
As there are multiple systems involved, user at one site can
utilize the resources of systems at other sites for resource-intensive tasks.
2.
Fast processing.
3.
Less load on the Host Machine.
REAL-TIME
OPERATING SYSTEM
It is defined as an operating system known to give maximum
time for each of the critical operations that it performs, like OS calls and
interrupt handling.
The Real-Time Operating system which guarantees the maximum
time for critical operations and complete them on time are referred to as Hard Real-Time Operating Systems.
While the real-time operating systems that can only
guarantee a maximum of the time, i.e. the critical task will get priority over
other tasks, but no assurity of completeing it in a defined time. These systems
are referred to as Soft Real-Time
Operating Systems.
CPU Scheduling
CPU scheduling is a process which allows one process to use
the CPU while the execution of another process is on hold(in waiting state) due
to unavailability of any resource like I/O etc, thereby making full use of CPU.
The aim of CPU scheduling is to make the system efficient, fast and fair.
Scheduling
Criteria
There are many different criterias to check when
considering the "best" scheduling algorithm :
·
CPU utilization
To make out the best use of CPU and not to waste any CPU
cycle, CPU would be working most of the time(Ideally 100% of the time).
Considering a real system, CPU usage should range from 40% (lightly loaded) to
90% (heavily loaded.)
·
Throughput
It is the total number of processes completed per unit time
or rather say total amount of work done in a unit of time. This may range from
10/second to 1/hour depending on the specific processes.
·
Turnaround time
It is the amount of time taken to execute a particular
process, i.e. The interval from time of submission of the process to the time
of completion of the process(Wall clock time).
·
Waiting time
The sum of the periods spent waiting in the ready queue
amount of time a process has been waiting in the ready queue to acquire get
control on the CPU.
·
Load average
It is the average number of processes residing in the ready
queue waiting for their turn to get into the CPU.
·
Response time
Amount of time it takes from when a request was submitted
until the first response is produced. Remember, it is the time till the first
response and not the completion of process execution(final response).
In general CPU utilization and Throughput are maximized and
other factors are reduced for proper optimization.


Process state
As a process executes, it changes state. The state of a process is defined in part by the
current activity of that process. A process may be in one of the following
states:
• New. The process is being created.
• Running. Instructions are being executed.
• Waiting. The process is waiting for some event to occur (such as
an I/O completion or reception of a signal).
• Ready. The process is waiting to be assigned to a processor.
• Terminated. The process has finished execution.

process control block(PCB)
Each process is represented in the operating system by a process control block(PCB) —also called a task
control block. A PCB is shown in Figure 3.3. It contains many pieces of information
associated with a specific process, including these:
Process state. The
state may be new, ready, running, waiting, halted, and so on.
• Program
counter. The counter indicates the
address of the next instruction to be executed for this process.
• CPU
registers. The registers vary in number
and type, depending on the computer architecture. They include accumulators,
index registers, stack pointers, and general-purpose registers, plus any
condition-code information. Along with the program counter, this state
information must be saved when an interrupt occurs, to allow the process to be
continued correctly afterward (Figure 3.4).
• CPU-scheduling
information. This information includes a
process priority, pointers to scheduling queues, and any other scheduling
parameters. (Chapter 6 describes process scheduling.)
• Memory-management
information. This information may
include such items as the value of the base and limit registers and the page
tables, or the segment tables, depending on the memory system used by the
operating system.
Accounting information.
This information includes the amount of CPU and real time used, time limits,
account numbers, job or process numbers, and so on.
• I/O
status information. This information
includes the list of I/O devices allocated to the process, a list of open
files, and so on.


Multicore Programming
Earlier in the history of computer design,
in response to the need for more computing performance, single-CPU systems
evolved into multi-CPU systems. A more recent, similar trend in system design
is to place multiple computing cores on a single chip. Each core appears as a
separate processor to the operating system (Section 1.3.2). Whether the cores
appear across CPU chips or within CPU chips, we call these systems multicore or multiprocessor systems.

Scheduling
Algorithms
We'll discuss four major scheduling algorithms here which
are following :
1.
First Come First Serve(FCFS) Scheduling
2.
Shortest-Job-First(SJF) Scheduling
3.
Priority Scheduling
4.
Round Robin(RR) Scheduling
5.
Multilevel Queue Scheduling
First
Come First Serve(FCFS) Scheduling
·
Jobs are executed on first come, first serve basis.
·
Easy to understand and implement.
·
Poor in performance as average wait time is high.

Shortest-Job-First(SJF) Scheduling
·
Best approach to minimize waiting time.
·
Actual time taken by the process is already known to processor.
·
Impossible to implement.

In Preemptive Shortest Job First Scheduling, jobs are put
into ready queue as they arrive, but as a process with short burst time
arrives, the existing process is preemptied.

Priority
Scheduling
·
Priority is assigned for each process.
·
Process with highest priority is executed first and so on.
·
Processes with same priority are executed in FCFS manner.
·
Priority can be decided based on memory requirements, time
requirements or any other resource requirement.

Round
Robin(RR) Scheduling
·
A fixed time is allotted to each process, called quantum, for execution.
·
Once a process is executed for given time period that process is
preemptied and other process executes for given time period.
·
Context switching is used to save states of preemptied processes.

Multilevel
Queue Scheduling
·
Multiple queues are maintained for processes.
·
Each queue can have its own scheduling algorithms.
·
Priorities are assigned to each queue.
What are Threads?
Thread is an execution unit which consists of its own
program counter, a stack, and a set of registers. Threads are also known as
Lightweight processes. Threads are popular way to improve application through
parallelism. The CPU switches rapidly back and forth among the threads giving
illusion that the threads are running in parallel.
As each thread has its own independent resource for process
execution, multpile processes can be executed parallely by increasing number of
threads.

Types
of Thread
There are two types of threads :
·
User Threads
·
Kernel Threads
User threads, are
above the kernel and without kernel support. These are the threads that
application programmers use in their programs.
Kernel threads are supported within the kernel of the OS itself. All
modern OSs support kernel level threads, allowing the kernel to perform
multiple simultaneous tasks and/or to service multiple kernel system calls
simultaneously.
Process Synchronization
Process Synchronization means sharing system resources by
processes in a such a way that, Concurrent access to shared data is handled
thereby minimizing the chance of inconsistent data. Maintaining data
consistency demands mechanisms to ensure synchronized execution of cooperating
processes.
Process Synchronization was introduced to handle problems
that arose while multiple process executions. Some of the problems are
discussed below.
Critical
Section Problem
A Critical Section is a code segment that accesses shared
variables and has to be executed as an atomic action. It means that in a group
of cooperating processes, at a given point of time, only one process must be
executing its critical section. If any other process also wants to execute its critical
section, it must wait until the first one finishes.

Solution
to Critical Section Problem
A solution to the critical section problem must satisfy the
following three conditions :
1.
Mutual Exclusion
Out of a group of cooperating processes, only one process
can be in its critical section at a given point of time.
2.
Progress
If no process is in its critical section, and if one or
more threads want to execute their critical section then any one of these
threads must be allowed to get into its critical section.
3.
Bounded Waiting
After a process makes a request for getting into its
critical section, there is a limit for how many other processes can get into
their critical section, before this process's request is granted. So after the
limit is reached, system must grant the process permission to get into its
critical section.

Synchronization
Hardware
Many systems provide hardware support for critical section
code. The critical section problem could be solved easily in a single-processor
environment if we could disallow interrupts to occur while a shared variable or
resource is being modified.
In this manner, we could be sure that the current sequence
of instructions would be allowed to execute in order without pre-emption.
Unfortunately, this solution is not feasible in a multiprocessor environment.
Disabling interrupt on a multiprocessor environment can be
time consuming as the message is passed to all the processors.
This message transmission lag, delays entry of threads into
critical section and the system efficiency decreases.
Mutex
Locks (process synchronization)
As the synchronization hardware solution is not easy to
implement fro everyone, a strict software approach called Mutex Locks was
introduced. In this approach, in the entry section of code, a LOCK is acquired
over the critical resources modified and used inside critical section, and in
the exit section that LOCK is released.
As the resource is locked while a process executes its
critical section hence no other process can access it.
Semaphores
(process synchronization)
A semaphore S is an integer variable that, apart from initialization,
is accessed only through two standard atomic operations: wait() and signal() . This integer variable is called semaphore. The wait() operation was designated
by P() and signal() was originally
designated by V () respectively.
wait(S) {
while (S <= 0)
; // busy wait
S--;
}
The definition of signal() is as follows:
signal(S) {
S++;
}
The classical definition of wait and signal are :
·
Wait : decrement the value of its argument S as soon as it would
become non-negative.
·
Signal : increment the value of its argument, S as an individual
operation.
Properties
of Semaphores
1.
Simple
2.
Works with many processes
3.
Can have many different critical sections with different
semaphores
4.
Each critical section has unique access semaphores
5.
Can permit multiple processes into the critical section at once,
if desirable.
Types
of Semaphores
Semaphores are mainly of two types:
1.
Binary Semaphore
It is a special form of semaphore used for implementing
mutual exclusion, hence it is often called Mutex. A binary
semaphore is initialized to 1 and only takes the value 0 and 1 during execution
of a program.
2.
Counting Semaphores
These are used to implement bounded concurrency.
Limitations
of Semaphores
1.
Priority Inversion is a big limitation os semaphores.
2.
Their use is not enforced, but is by convention only.
3.
With improper use, a process may block indefinitely. Such a
situation is called Deadlock. We will be studying deadlocks in details in
coming lessons.
What is a Deadlock?
Deadlocks are a set of blocked processes each holding a
resource and waiting to acquire a resource held by another process.




How
to avoid Deadlocks
Deadlocks can be avoided by avoiding at least one of the
four conditions, because all this four conditions are required simultaneously
to cause deadlock.
1.
Mutual Exclusion
Resources shared such as read-only files do not lead to
deadlocks but resources, such as printers and tape drives, requires exclusive
access by a single process.
2.
Hold and Wait
In this condition processes must be
prevented from holding one or more resources while simultaneously waiting for
one or more others.
3.
No Preemption
Preemption of process resource allocations can avoid the
condition of deadlocks, where ever possible.
4.
Circular Wait
Circular wait can be avoided if we number all resources,
and require that processes request resources only in strictly increasing (or
decreasing) order.
Handling
Deadlock
The above points focus on preventing deadlocks. But what to
do once a deadlock has occured. Following three strategies can be used to
remove deadlock after its occurrence.
1.
Preemption
We can take a resource from one process and give it to
other. This will resolve the deadlock situation, but sometimes it does causes
problems.
2.
Rollback
In situations where deadlock is a real possibility, the
system can periodically make a record of the state of each process and when
deadlock occurs, roll everything back to the last checkpoint, and restart, but
allocating resources differently so that deadlock does not occur.
3.
Kill one or more processes
This is the simplest way, but it works.
What is a Livelock?
There is a variant of deadlock called livelock. This is a
situation in which two or more processes continuously change their state in
response to changes in the other process(es) without doing any useful work.
This is similar to deadlock in that no progress is made but differs in that
neither process is blocked or waiting for anything.
Deadlock
characterization :-
Resource-Allocation
Graph
·
In some cases deadlocks can be understood more clearly through the
use of Resource-Allocation
Graphs, having the following properties:
o A
set of resource categories, { R1, R2, R3, . . ., RN }, which appear as square
nodes on the graph. Dots inside the resource nodes indicate specific instances
of the resource. ( E.g. two dots might represent two laser printers. )
o A
set of processes, { P1, P2, P3, . . ., PN }
o Request Edges - A set of directed arcs from Pi to Rj,
indicating that process Pi has requested Rj, and is currently waiting for that
resource to become available.
o Assignment Edges - A set of directed arcs from Rj to Pi
indicating that resource Rj has been allocated to process Pi, and that Pi is
currently holding resource Rj.
o Note
that a request edge can be converted into an assignment edge by reversing the direction of the arc
when the request is granted. ( However note also that request edges point
to the category box, whereas assignment edges emanate from a particular
instance dot within the box. )
o For
example:

Figure - Resource allocation graph
·
If a resource-allocation graph contains no cycles, then the system
is not deadlocked. ( When looking for cycles, remember that these are directed graphs. ) See the example in Figure
above.
·
If a resource-allocation graph does contain cycles AND each resource category contains only a
single instance, then a deadlock exists.
·
If a resource category contains more than one instance, then the
presence of a cycle in the resource-allocation graph indicates the possibility of a deadlock, but does not guarantee
one. Consider, for example, Figures and below:

Figure - Resource allocation graph with a deadlock

Figure - Resource allocation graph with a cycle but no deadlock
Methods
for Handling Deadlocks
·
Generally speaking there are three ways of handling deadlocks:
1. Deadlock
prevention or avoidance - Do not allow the system to get into a deadlocked
state.
2. Deadlock
detection and recovery - Abort a process or preempt some resources when deadlocks
are detected.
3. We
can ignore the problem altogether and pretend that deadlocks never occur in the
system.
Deadlock
Prevention
Deadlocks can be prevented by preventing at least one of the four
required conditions:
Mutual Exclusion
·
Shared resources such as read-only files do not lead to deadlocks.
·
Unfortunately some resources, such as printers and tape drives,
require exclusive access by a single process.
Hold and Wait
To prevent this condition processes must be prevented from holding
one or more resources while simultaneously waiting for one or more others.
There are several possibilities for this:
o Require
that all processes request all resources at one time. This can be wasteful of
system resources if a process needs one resource early in its execution and
doesn't need some other resource until much later.
o Require
that processes holding resources must release them before requesting new
resources, and then re-acquire the released resources along with the new ones
in a single new request. This can be a problem if a process has partially
completed an operation using a resource and then fails to get it re-allocated
after releasing it.
o Either
of the methods described above can lead to starvation if a process requires one
or more popular resources.
No
Preemption
Preemption of process resource allocations can prevent this
condition of deadlocks, when it is possible.
o One
approach is that if a process is forced to wait when requesting a new resource,
then all other resources previously held by this process are implicitly
released, ( preempted ), forcing this process to re-acquire the old
resources along with the new resources in a single request, similar to the
previous discussion.
o Another
approach is that when a resource is requested and not available, then the
system looks to see what other processes currently have those resources and are themselves blocked waiting for
some other resource. If such a process is found, then some of their resources
may get preempted and added to the list of resources for which the process is
waiting.
o Either
of these approaches may be applicable for resources whose states are easily
saved and restored, such as registers and memory, but are generally not
applicable to other devices such as printers and tape drives.
Circular
Wait
·
One way to avoid circular wait is to number all resources, and to
require that processes request resources only in strictly increasing ( or
decreasing ) order.
·
In other words, in order to request resource Rj, a process must
first release all Ri such that i >= j.
·
One big challenge in this scheme is determining the relative
ordering of the different resources
Deadlock Avoidance
·
The general idea behind deadlock avoidance is to prevent deadlocks
from ever happening, by preventing at least one of the aforementioned
conditions.
·
This requires more information about each process, AND tends to
lead to low device utilization. ( I.e. it is a conservative approach. )
·
In some algorithms the scheduler only needs to know the maximum number
of each resource that a process might potentially use. In more complex
algorithms the scheduler can also take advantage of the schedule of exactly what resources may be
needed in what order.
·
When a scheduler sees that starting a process or granting resource
requests may lead to future deadlocks, then that process is just not started or
the request is not granted.
·
A resource allocation state is defined by the number of available
and allocated resources, and the maximum requirements of all processes in the
system.
Safe
State
·
A state is safe if the system can allocate all
resources requested by all processes ( up to their stated maximums ) without
entering a deadlock state.
·
More formally, a state is safe if there exists a safe sequence of processes { P0, P1, P2, ...,
PN } such that all of the resource requests for Pi can be granted using
the resources currently allocated to Pi and all processes Pj where j < i. (
I.e. if all the processes prior to Pi finish and free up their resources, then
Pi will be able to finish also, using the resources that they have freed up. )
·
If a safe sequence does not exist, then the system is in an unsafe
state, which MAY lead to deadlock. ( All safe states
are deadlock free, but not all unsafe states lead to deadlocks. )

Figure - Safe, unsafe, and deadlocked state spaces.
·
For example, consider a system with 12 tape drives, allocated as
follows. Is this a safe state? What is the safe sequence?
|
|
Maximum
Needs |
Current
Allocation |
|
P0 |
10 |
5 |
|
P1 |
4 |
2 |
|
P2 |
9 |
2 |
·
What happens to the above table if process P2 requests and is
granted one more tape drive?
·
Key to the safe state approach is that when a request is made for
resources, the request is granted only if the resulting allocation state is a
safe one.
Resource-Allocation
Graph Algorithm
·
If resource categories have only single instances of their
resources, then deadlock states can be detected by cycles in the
resource-allocation graphs.
·
In this case, unsafe states can be recognized and avoided by
augmenting the resource-allocation graph with claim
edges, noted by dashed lines, which point from a process to a resource
that it may request in the future.
·
In order for this technique to work, all claim edges must be added
to the graph for any particular process before that process is allowed to
request any resources. ( Alternatively, processes may only make requests
for resources for which they have already established claim edges, and claim
edges cannot be added to any process that is currently holding
resources. )
·
When a process makes a request, the claim edge Pi->Rj is
converted to a request edge. Similarly when a resource is released, the
assignment reverts back to a claim edge.
·
This approach works by denying requests that would produce cycles
in the resource-allocation graph, taking claim edges into effect.
· Consider for example what happens when process P2 requests resource R2:

Figure - Resource allocation graph for deadlock avoidance
·
The resulting resource-allocation graph would have a cycle in it,
and so the request cannot be granted.

Figure 7.8 - An unsafe state in a resource allocation graph
Banker's
Algorithm
·
For resource categories that contain more than one instance the
resource-allocation graph method does not work, and more complex ( and
less efficient ) methods must be chosen.
·
The Banker's Algorithm gets its name because it is a method that
bankers could use to assure that when they lend out resources they will still
be able to satisfy all their clients. ( A banker won't loan out a little
money to start building a house unless they are assured that they will later be
able to loan out the rest of the money to finish the house. )
·
When a process starts up, it must state in advance the maximum
allocation of resources it may request, up to the amount available on the
system.
·
When a request is made, the scheduler determines whether granting
the request would leave the system in a safe state. If not, then the process
must wait until the request can be granted safely.
·
The banker's algorithm relies on several key data structures: (
where n is the number of processes and m is the number of resource categories.
)
o Available[
m ] indicates how many resources are currently available of each type.
o Max[
n ][ m ] indicates the maximum demand of each process of each resource.
o Allocation[
n ][ m ] indicates the number of each resource category allocated to each
process.
o Need[
n ][ m ] indicates the remaining resources needed of each type for each
process. ( Note that Need[ i ][ j ] =
Max[ i ][ j ] - Allocation[ i ][ j ]
for all i, j. )
·
For simplification of discussions, we make the following notations
/ observations:
o One
row of the Need vector, Need[ i ], can be treated as a vector corresponding to
the needs of process i, and similarly for Allocation and Max.
o A
vector X is considered to be <= a vector Y if X[ i ] <=
Y[ i ] for all i.

7.5.3.3
An Illustrative Example
·
Consider the following situation:

·
And now consider what happens if process P1 requests 1 instance of
A and 2 instances of C. ( Request[ 1 ] = ( 1, 0, 2 ) )

·
What about requests of ( 3, 3,0 ) by P4? or ( 0, 2, 0 ) by P0? Can
these be safely granted? Why or why not?
Deadlock
Detection
·
If deadlocks are not avoided, then another approach is to detect
when they have occurred and recover somehow.
·
In addition to the performance hit of constantly checking for
deadlocks, a policy / algorithm must be in place for recovering from deadlocks,
and there is potential for lost work when processes must be aborted or have
their resources preempted.
Single
Instance of Each Resource Type
·
If each resource category has a single instance, then we can use a
variation of the resource-allocation graph known as a wait-for graph.
·
A wait-for graph can be constructed from a resource-allocation
graph by eliminating the resources and collapsing the associated edges, as
shown in the figure below.
·
An arc from Pi to Pj in a wait-for graph indicates that process Pi
is waiting for a resource that process Pj is currently holding.

Figure - (a) Resource allocation graph. (b) Corresponding wait-for graph
·
As before, cycles in the wait-for graph indicate deadlocks.
·
This algorithm must maintain the wait-for graph, and periodically
search it for cycles.
Several
Instances of a Resource Type
·
The detection algorithm outlined here is essentially the same as
the Banker's algorithm, with two subtle differences:
o In
step 1, the Banker's Algorithm sets Finish[ i ] to false for all i. The
algorithm presented here sets Finish[ i ] to false only if Allocation[ i ] is
not zero. If the currently allocated resources for this process are zero, the
algorithm sets Finish[ i ] to true. This is essentially assuming that IF all of
the other processes can finish, then this process can finish also. Furthermore,
this algorithm is specifically looking for which processes are involved in a
deadlock situation, and a process that does not have any resources allocated
cannot be involved in a deadlock, and so can be removed from any further
consideration.
o Steps
2 and 3 are unchanged
o In
step 4, the basic Banker's Algorithm says that if Finish[ i ] == true for all
i, that there is no deadlock. This algorithm is more specific, by stating that
if Finish[ i ] == false for any process Pi, then that process is specifically
involved in the deadlock which has been detected.
·
Consider, for example, the following state, and determine if it is
currently deadlocked:

·
Now suppose that process P2 makes a request for an additional
instance of type C, yielding the state shown below. Is the system now
deadlocked?

Detection-Algorithm
Usage
·
When should the deadlock detection be done? Frequently, or
infrequently?
·
The answer may depend on how frequently deadlocks are expected to
occur, as well as the possible consequences of not catching them immediately.
·
There are two obvious approaches, each with trade-offs:
1. Do
deadlock detection after every resource allocation which cannot be immediately
granted. This has the advantage of detecting the deadlock right away, while the
minimum number of processes are involved in the deadlock. ( One might consider
that the process whose request triggered the deadlock condition is the
"cause" of the deadlock, but realistically all of the processes in
the cycle are equally responsible for the resulting deadlock. ) The down side
of this approach is the extensive overhead and performance hit caused by
checking for deadlocks so frequently.
2. Do
deadlock detection only when there is some clue that a deadlock may have
occurred, such as when CPU utilization reduces to 40% or some other magic
number. The advantage is that deadlock detection is done much less frequently,
but the down side is that it becomes impossible to detect the processes
involved in the original deadlock, and so deadlock recovery can be more
complicated and damaging to more processes.
Recovery
From Deadlock
·
There are three basic approaches to recovery from deadlock:
1. Inform
the system operator, and allow him/her to take manual intervention.
2. Terminate
one or more processes involved in the deadlock
3. Preempt
resources.
Process
Termination
·
Two basic approaches, both of which recover resources allocated to
terminated processes:
o Terminate
all processes involved in the deadlock. This definitely solves the deadlock,
but at the expense of terminating more processes than would be absolutely
necessary.
o Terminate
processes one by one until the deadlock is broken. This is more conservative,
but requires doing deadlock detection after each step.
·
In the latter case there are many factors that can go into
deciding which processes to terminate next:
1. Process
priorities.
2. How
long the process has been running, and how close it is to finishing.
3. How
many and what type of resources is the process holding. ( Are they easy to
preempt and restore? )
4. How
many more resources does the process need to complete.
5. How
many processes will need to be terminated
6. Whether
the process is interactive or batch.
7. (
Whether or not the process has made non-restorable changes to any resource. )
Resource
Preemption
·
When preempting resources to relieve deadlock, there are three
important issues to be addressed:
1. Selecting a victim - Deciding which resources to preempt
from which processes involves many of the same decision criteria outlined
above.
2. Rollback - Ideally one would like to roll back a
preempted process to a safe state prior to the point at which that resource was
originally allocated to the process. Unfortunately it can be difficult or
impossible to determine what such a safe state is, and so the only safe
rollback is to roll back all the way back to the beginning. ( I.e. abort the
process and make it start over. )
3. Starvation - How do you guarantee that a process
won't starve because its resources are constantly being preempted? One option
would be to use a priority system, and increase the priority of a process every
time its resources get preempted. Eventually it should get a high enough
priority that it won't get preempted any more.
Batch processing
Batch processing is a technique in which an Operating System collects the programs and data together in a batch

before processing starts.
Multitasking
Multitasking is when multiple jobs are executed by the CPU
simultaneously by switching between them. Switches occur so frequently that the
users may interact with each program while it is running.

Multiprogramming
Sharing
the processor, when two or more programs reside in memory at the same time, is
referred as multiprogramming.
Multiprogramming assumes a single shared processor. Multiprogramming increases
CPU utilization by organizing jobs so that the CPU always has one to execute.
The
following figure shows the memory layout for a multiprogramming system.

An
OS does the following activities related to multiprogramming.
Spooling
Spooling
is an acronym for simultaneous peripheral operations on line. Spooling refers
to putting data of various I/O jobs in a buffer. This buffer is a special area
in memory or hard disk which is accessible to I/O devices.
An
operating system does the following activities related to distributed
environment −
·
Handles I/O device
data spooling as devices have different data access rates.
·
Maintains the spooling
buffer which provides a waiting station where data can rest while the slower
device catches up.
·
Maintains parallel
computation because of spooling process as a computer can perform I/O in
parallel fashion. It becomes possible to have the computer read data from a
tape, write data to disk and to write out to a tape printer while it is doing
its computing task.

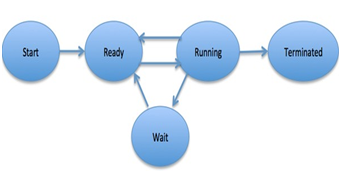
Process Life Cycle
When
a process executes, it passes through different states. These stages may differ
in different operating systems, and the names of these states are also not
standardized.
In
general, a process can have one of the following five states at a time.
|
SL |
State & Description |
|
1 |
Start This is the initial state when a process is first started/created. |
|
2 |
Ready The process is waiting to be assigned to a processor. Ready processes
are waiting to have the processor allocated to them by the operating system
so that they can run. Process may come into this state after Start state or while
running it by but interrupted by the scheduler to assign CPU to some other
process. |
|
3 |
Running Once the process has been assigned to a processor by the OS scheduler,
the process state is set to running and the processor executes its
instructions. |
|
4 |
Waiting Process moves into the waiting state if it needs to wait for a resource,
such as waiting for user input, or waiting for a file to become available. |
|
5 |
Terminated or Exit Once the process finishes its execution, or it is terminated by the
operating system, it is moved to the terminated state where it waits to be
removed from main memory. |
Process Control Block (PCB)
A
Process Control Block is a data structure maintained by the Operating System
for every process. The PCB is identified by an integer process ID (PID). A PCB
keeps all the information needed to keep track of a process as listed below in
the table −
|
Sl |
Information & Description |
|
1 |
Process State The current state of the process i.e., whether it is ready, running,
waiting, or whatever. |
|
2 |
Process privileges This is required to allow/disallow access to system resources. |
|
3 |
Process ID Unique identification for each of the process in the operating system. |
|
4 |
Pointer A pointer to parent process. |
|
5 |
Program Counter Program Counter is a pointer to the address of the next instruction to
be executed for this process. |
|
6 |
CPU registers Various CPU registers where process need to be stored for execution
for running state. |
|
7 |
CPU Scheduling Information Process priority and other scheduling information which is required to
schedule the process. |
|
8 |
Memory management information This includes the information of page table, memory limits, Segment
table depending on memory used by the operating system. |
|
9 |
Accounting information This includes the amount of CPU used for process execution, time
limits, execution ID etc. |
|
10 |
IO status information This includes a list of I/O devices allocated to the process. |
The
architecture of a PCB is completely dependent on Operating System and may
contain different information in different operating systems. Here is a
simplified diagram of a PCB −

The
PCB is maintained for a process throughout its lifetime, and is deleted once
the process terminates.
What is a Process?
A program in the execution is called a Process. Process is
not the same as program. A process is more than a program code. A process is an
'active' entity as opposed to program which is considered to be a 'passive'
entity. Attributes held by process include hardware state, memory, CPU etc.
PROCESS STATE
Processes can be any of the following states :
·
New - The process is in the stage of being
created.
·
Ready - The process has all the resources
available that it needs to run, but the CPU is not currently working on this
process's instructions.
·
Running - The CPU is working on this process's
instructions.
·
Waiting - The process cannot run at the moment,
because it is waiting for some resource to become available or for some event
to occur.
·
Terminated - The process has completed.

PROCESS CONTROL BLOCK
There is a Process Control Block for each process,
enclosing all the information about the process. It is a data structure, which
contains the following :
·
Process State - It can be running, waiting etc.
·
Process ID and parent process ID.
·
CPU registers and Program Counter. Program Counter holds the address of the next
instruction to be executed for that process.
·
CPU Scheduling information - Such as priority information and
pointers to scheduling queues.
·
Memory Management information - Eg. page tables or segment tables.
·
Accounting information - user and kernel CPU time consumed, account
numbers, limits, etc.
·
I/O Status information - Devices allocated, open file tables, etc.

Process Scheduling Definition
The process scheduling
is the activity of the process manager that handles the removal of the running
process from the CPU and the selection of another process on the basis of a
particular strategy.
The Operating System
maintains the following important process scheduling queues −
·
Job
queue − This queue keeps
all the processes in the system.
·
Ready
queue − This queue keeps
a set of all processes residing in main memory, ready and waiting to execute. A
new process is always put in this queue.
·
Device
queues − The processes
which are blocked due to unavailability of an I/O device constitute this queue.

Context Switch
A context switch is the
mechanism to store and restore the state or context of a CPU in Process Control
block so that a process execution can be resumed from the same point at a later
time. Using this technique, a context switcher enables multiple processes to
share a single CPU. Context switching is an essential part of a multitasking
operating system features.
Difference between Process and Thread
|
Sl |
Process |
Thread |
|
1 |
Process is heavy weight or resource intensive. |
Thread is light weight, taking lesser resources than a process. |
|
2 |
Process switching needs interaction with operating system. |
Thread switching does not need to interact with operating
system. |
|
3 |
In multiple processing environments, each process executes the
same code but has its own memory and file resources. |
All threads can share same set of open files, child processes. |
|
4 |
If one process is blocked, then no other process can execute
until the first process is unblocked. |
While one thread is blocked and waiting, a second thread in
the same task can run. |
|
5 |
Multiple processes without using threads use more resources. |
Multiple threaded processes use fewer resources. |
|
6 |
In multiple processes each process operates independently of
the others. |
One thread can read, write or change another thread's data. |
Advantages of Thread
·
Threads minimize the context switching time.
·
Use of threads provides concurrency within a process.
·
Efficient communication.
·
It is more economical to create and context switch threads.
·
Threads allow utilization of multiprocessor architectures to a
greater scale and efficiency.

Difference between User-Level &
Kernel-Level Thread
|
S.N. |
User-Level Threads |
Kernel-Level Thread |
|
1 |
User-level threads are faster to create and manage. |
Kernel-level threads are slower to create and manage. |
|
2 |
Implementation is by a thread library at the user level. |
Operating system supports creation of Kernel threads. |
|
3 |
User-level thread is generic and can run on any operating
system. |
Kernel-level thread is specific to the operating system. |
|
4 |
Multi-threaded applications cannot take advantage of
multiprocessing. |
Kernel routines themselves can be multithreaded. |
Swapping
Swapping
is a mechanism in which a process can be swapped temporarily out of main memory
(or move) to secondary storage (disk) and make that memory available to other
processes. At some later time, the system swaps back the process from the
secondary storage to main memory.
Though
performance is usually affected by swapping process but it helps in running
multiple and big processes in parallel and that's the reason Swapping is also known as a technique for memory compaction.

Fragmentation
As
processes are loaded and removed from memory, the free memory space is broken
into little pieces. It happens after sometimes that processes cannot be
allocated to memory blocks considering their small size and memory blocks
remains unused. This problem is known as Fragmentation.
Fragmentation
is of two types −
|
Sl |
Fragmentation & Description |
|
1 |
External fragmentation Total memory space is enough to satisfy a request or to reside a
process in it, but it is not contiguous, so it cannot be used. |
|
2 |
Internal fragmentation Memory block assigned to process is bigger. Some portion of memory is
left unused, as it cannot be used by another process. |
The
following diagram shows how fragmentation can cause waste of memory and a
compaction technique can be used to create more free memory out of fragmented
memory −

External
fragmentation can be reduced by compaction or shuffle memory contents to place
all free memory together in one large block. To make compaction feasible,
relocation should be dynamic.
The
internal fragmentation can be reduced by effectively assigning the smallest
partition but large enough for the process.
Paging
A
computer can address more memory than the amount physically installed on the
system. This extra memory is actually called virtual memory and it is a section
of a hard that's set up to emulate the computer's RAM. Paging technique plays
an important role in implementing virtual memory.
Paging
is a memory management technique in which process address space is broken into
blocks of the same size called pages (size is power of 2, between 512 bytes and 8192 bytes). The
size of the process is measured in the number of pages.
Similarly,
main memory is divided into small fixed-sized blocks of (physical) memory
called frames and the size of a
frame is kept the same as that of a page to have optimum utilization of the
main memory and to avoid external fragmentation.

Address Translation
Page
address is called logical address and represented by page number and the offset.
Logical Address = Page number + page offsetFrame
address is called physical address and represented by a frame number and the offset.
Physical Address = Frame number + page offsetA
data structure called page map table is used to keep track of the relation between a page of a
process to a frame in physical memory.

When
the system allocates a frame to any page, it translates this logical address
into a physical address and create entry into the page table to be used
throughout execution of the program.
Virtual Memory
Virtual Memory is a space where large programs can store
themselves in form of pages while their execution and only the required pages
or portions of processes are loaded into the main memory. This technique is
useful as large virtual memory is provided for user programs when a very small
physical memory is there.
In real scenarios, most processes never need all their
pages at once, for following reasons :
·
Error handling code is not needed unless that specific error
occurs, some of which are quite rare.
·
Arrays are often over-sized for worst-case scenarios, and only a
small fraction of the arrays are actually used in practice.
·
Certain features of certain programs are rarely used.
Benefits of having Virtual Memory :
1.
Large programs can be written, as virtual space available is huge
compared to physical memory.
2.
Less I/O required, leads to faster and easy swapping of processes.
3.
More physical memory available, as programs are stored on virtual
memory, so they occupy very less space on actual physical memory.
Demand Paging
The basic idea behind demand paging is that when a process
is swapped in, its pages are not swapped in all at once. Rather they are
swapped in only when the process needs them(On demand). This is termed as lazy
swapper, although a pager is a more accurate term.

Initially only those pages are loaded which will be
required the process immediately.
The pages that are not moved into the memory, are marked as
invalid in the page table. For an invalid entry the rest of the table is empty.
In case of pages that are loaded in the memory, they are marked as valid along
with the information about where to find the swapped out page.
When the process requires any of the page that is not
loaded into the memory, a page fault trap is triggered and following steps are
followed,
1.
The memory address which is requested by the process is first
checked, to verify the request made by the process.
2.
If its found to be invalid, the process is terminated.
3.
In case the request by the process is valid, a free frame is
located, possibly from a free-frame list, where the required page will be
moved.
4.
A new operation is scheduled to move the necessary page from disk
to the specified memory location. ( This will usually block the process on an
I/O wait, allowing some other process to use the CPU in the meantime. )
5.
When the I/O operation is complete, the process's page table is
updated with the new frame number, and the invalid bit is changed to valid.
6.
The instruction that caused the page fault must now be restarted
from the beginning.
page fault :- if the
process tries to access a page that was not brought into memory? Access to a
page marked invalid causes a page fault.
Page Replacement Algorithm
Page
replacement algorithms are the techniques using which an Operating System
decides which memory pages to swap out, write to disk when a page of memory
needs to be allocated. Paging happens whenever a page fault occurs and a free
page cannot be used for allocation purpose accounting to reason that pages are
not available or the number of free pages is lower than required pages.
Reference String
The
string of memory references is called reference string. Reference strings are
generated artificially or by tracing a given system and recording the address
of each memory reference. The latter choice produces a large number of data,
where we note two things.
·
For a given page size,
we need to consider only the page number, not the entire address.
·
If we have a reference
to a page p, then any
immediately following references to page p will never cause a
page fault. Page p will be in memory after the first reference; the immediately
following references will not fault.
·
For example, consider
the following sequence of addresses − 123,215,600,1234,76,96
·
If page size is 100,
then the reference string is 1,2,6,12,0,0
First In First Out (FIFO) algorithm
·
Oldest page in main
memory is the one which will be selected for replacement.
·
Easy to implement,
keep a list, replace pages from the tail and add new pages at the head.

Optimal Page algorithm
·
An optimal
page-replacement algorithm has the lowest page-fault rate of all algorithms. An
optimal page-replacement algorithm exists, and has been called OPT or MIN.
·
Replace the page that
will not be used for the longest period of time. Use the time when a page is to
be used.

Least Recently Used (LRU)
algorithm
·
Page which has not
been used for the longest time in main memory is the one which will be selected
for replacement.
·
Easy to implement,
keep a list, replace pages by looking back into time.

Page Buffering algorithm
·
To get a process start quickly, keep a pool of free frames.
·
On page fault, select a page to be replaced.
·
Write the new page in the frame of free pool, mark the page table
and restart the process.
·
Now write the dirty page out of disk and place the frame holding
replaced page in free pool.
Least frequently Used(LFU)
algorithm
·
The page with the
smallest count is the one which will be selected for replacement.
·
This algorithm suffers
from the situation in which a page is used heavily during the initial phase of
a process, but then is never used again.
Most frequently Used(MFU)
algorithm
·
This algorithm is
based on the argument that the page with the smallest count was probably just
brought in and has yet to be used.
Components of Linux System
Linux Operating System has
primarily three components
·
Kernel − Kernel is the core part of Linux. It is
responsible for all major activities of this operating system. It consists of
various modules and it interacts directly with the underlying hardware. Kernel
provides the required abstraction to hide low level hardware details to system
or application programs.
·
System
Library − System libraries
are special functions or programs using which application programs or system
utilities accesses Kernel's features. These libraries implement most of the
functionalities of the operating system and do not requires kernel module's
code access rights.
·
System
Utility − System Utility
programs are responsible to do specialized, individual level tasks.

Architecture
The following illustration
shows the architecture of a Linux system −

The architecture of a
Linux System consists of the following layers −
·
Hardware
layer − Hardware
consists of all peripheral devices (RAM/ HDD/ CPU etc).
·
Kernel − It is the core component of Operating
System, interacts directly with hardware, provides low level services to upper
layer components.
·
Shell − An interface to kernel, hiding
complexity of kernel's functions from users. The shell takes commands from the
user and executes kernel's functions.
·
Utilities − Utility programs that provide the user
most of the functionalities of an operating systems.
Threading
Issues
The issues to consider in designing
multithreaded programs. The fork () and exec () System Calls, we described how
the fork() system call is used to create a separate, duplicate process. The
semantics of the fork () and exec () system calls change in a multithreaded
program.
If one thread in a program calls fork() , does the new process duplicate all
threads, or is the new process single-threaded? Some UNIX systems have chosen
to have two versions of fork() , one that duplicates all threads and another
that duplicates only the thread that invoked the fork() system call.
Fork()
The fork() system call is used to create processes. When a
process (a program in execution) makes a fork() call, an exact copy of the
process is created. Now there are two processes, one being the parent process and the
other being the child process.
//example.c#include void main() {intval; val = fork(); // line Aprintf(“%d”,val); // line B}
Exec()
The exec() system call is also used to create processes. But there
is one big difference between fork() and exec() calls. The fork() call creates a new
process while preserving the parent process. But, an exec() call replaces the
address space, text segment, data segment etc. of the current process with the
new process
//example2.c#include void main() {execl("/bin/ls", "ls", 0); // line Aprintf(“This text won’t be printed unless an error occurs in exec().”);}
File allocation method:-
Contiguous Allocation
Linked allocation
Indexed allocation
1.Contiguous
Allocation
Contiguous allocationrequires
that each file occupy a set of contiguous blocks on the disk. Disk addresses
define a linear ordering on the disk.

2.Linked allocation
Linked allocation solves all problems of contiguous
allocation. With linked allocation, each file is a linked list of disk blocks;
the disk blocks may be scattered anywhere on the disk.

3.Indexed allocation
Linked allocation solves the external-fragmentation
and size-declaration problems of contiguous allocation. However, in the absence
of a FAT, linked allocation cannot support efficient direct access, since the
pointers to the blocks are scattered with the blocks themselves all over the
disk and must be retrieved in order. Indexed
allocation solves this problem by bringing all the pointers together
into one location: the index block.


Indone in
linux/unix
Inode Definition. An inode is a data structure on a
filesystem on Linux and
other Unix-like operating systems that stores all the information about a file
except its name and its actual data. A data structure is a way of storing data
so that it can be used efficiently.

Free-Space
Management
1.Bit Vector
Frequently, the free-space list is implemented as a bit map or bit vector. Each block is represented by 1 bit. If the block is
free, the bit is 1; if the block is allocated, the bit is 0.
For example, consider a disk where blocks 2, 3, 4, 5, 8, 9, 10, 11, 12, 13, 17,
18, 25, 26, and 27 are free and the rest of the blocks are allocated. The
free-space bit map would be
001111001111110001100000011100000...
2. Linked List
Another approach to free-space management is to link
together all the free disk blocks, keeping a pointer to the first free block in
a special location on the disk and caching it in memory. This first block
contains a pointer to the next free disk block, and so on.

3.Grouping
A modification of the free-list approach stores the
addresses of n free blocks in the first free block. The first n−1
of these blocks are actually free. The last block contains the addresses of
other n free blocks, and so on.
4.Space Maps
Oracle’s ZFS
file system (found in Solaris and other operating systems) was designed
to encompass huge numbers of files, directories, and even file systems (in ZFS,
we can create file-system hierarchies).
What
is page fault? [eastern refinery buet
exam - 2016]
Operating System | Page Fault
Handling
A page fault occurs when a program attempts to
access data or code that is in its address space, but is not currently located
in the system RAM. So when page fault occurs then following sequence of events
happens :

§ The computer hardware traps to the kernel and
program counter (PC) is saved on the stack. Current instruction state
information is saved in CPU registers.
§ An assembly program is started to save the
general registers and other volatile information to keep the OS from destroying
it.
§ Operating system finds that a page fault has
occurred and tries to find out which virtual page is needed. Some times
hardware register contains this required information. If not, the operating
system must retrieve PC, fetch instruction and find out what it was doing when
the fault occurred.
§ Once virtual address caused page fault is known,
system checks to see if address is valid and checks if there is no protection
access problem.
§ If the virtual address is valid, the system
checks to see if a page frame is free. If no frames are free, the page replacement
algorithm is run to remove a page.
§ If frame selected is dirty, page is scheduled
for transfer to disk, context switch takes place, fault process is suspended
and another process is made to run until disk transfer is completed.
§ As soon as page frame is clean, operating system
looks up disk address where needed page is, schedules disk operation to bring
it in.
§ When disk interrupt indicates page has arrived,
page tables are updated to reflect its position, and frame marked as being in
normal state.
§ Faulting instruction is backed up to state it
had when it began and PC is reset. Faulting is scheduled, operating system
returns to routine that called it.
§ Assembly Routine reloads register and other
state information, returns to user space to continue execution.
What
is paging ?
Operating System | Paging
Paging is a memory management scheme that
eliminates the need for contiguous allocation of physical memory. This scheme
permits the physical address space of a process to be non – contiguous.
§ Logical Address or Virtual Address (represented
in bits): An address generated by the CPU
§ Logical Address Space or Virtual Address Space(
represented in words or bytes): The set of all logical addresses generated by a
program
§ Physical Address (represented in bits): An
address actually available on memory unit
§ Physical Address Space (represented in words or
bytes): The set of all physical addresses corresponding to the logical
addresses
Example:
§ If Logical Address = 31 bit, then Logical
Address Space = 231words = 2 G words (1 G = 230)
§ If Logical Address Space = 128 M words = 27 * 220 words,
then Logical Address = log2 227 = 27 bits
§ If Physical Address = 22 bit, then Physical
Address Space = 222words = 4 M words (1 M = 220)
§ If Physical Address Space = 16 M words = 24 * 220 words,
then Physical Address = log2 224 = 24 bits
The mapping from virtual to physical address is
done by the memory management unit (MMU) which is a hardware device and this
mapping is known as paging technique.
§ The Physical Address Space is conceptually
divided into a number of fixed-size blocks, called frames.
§ The Logical address Space is also splitted into
fixed-size blocks, called pages.
§ Page Size = Frame Size
Let us consider an example:
§ Physical Address = 12 bits, then Physical
Address Space = 4 K words
§ Logical Address = 13 bits, then Logical Address
Space = 8 K words
§ Page size = frame size = 1 K words (assumption)

Address generated by CPU is divided into
§ Page number(p): Number of bits required to represent the
pages in Logical Address Space or Page number
§ Page offset(d): Number of bits required to represent
particular word in a page or page size of Logical Address Space or word number
of a page or page offset.
Physical Address is divided into
§ Frame number(f): Number of bits required to represent the
frame of Physical Address Space or Frame number.
§ Frame offset(d): Number of bits required to represent
particular word in a frame or frame size of Physical Address Space or word
number of a frame or frame offset.
The hardware implementation of page table can be
done by using dedicated registers. But the usage of register for the page table
is satisfactory only if page table is small. If page table contain large number
of entries then we can use TLB(translation Look-aside buffer), a special, small,
fast look up hardware cache.
§ The TLB is associative, high speed memory.
§ Each entry in TLB consists of two parts: a tag
and a value.
§ When this memory is used, then an item is
compared with all tags simultaneously.If the item is found, then corresponding
value is returned.

Main memory access time = m
If page table are kept in main memory,
Effective access time = m(for page table) + m(for particular page in page table)

What is virtual memory ?
Virtual Memory is a storage
allocation scheme in which secondary memory can be addressed as though it were
part of main memory. The addresses a program may use to reference memory are
distinguished from the addresses the memory system uses to identify physical
storage sites, and program generated addresses are translated automatically to
the corresponding machine addresses.
The size of virtual storage is limited by the addressing scheme of the computer
system and amount of secondary memory is available not by the actual number of
the main storage locations.
It is a technique that is implemented using both
hardware and software. It maps memory addresses used by a program, called
virtual addresses, into physical addresses in computer memory.
1. All memory references within a process are
logical addresses that are dynamically translated into physical addresses at
run time. This means that a process can be swapped in and out of main memory
such that it occupies different places in main memory at different times during
the course of execution.
2. A process may be broken into number of pieces
and these pieces need not be continuously located in the main memory during
execution. The combination of dynamic run-time addres translation and use of
page or segment table permits this.
If these characteristics are present then, it is
not necessary that all the pages or segments are present in the main memory
during execution. This means that the required pages need to be loaded into
memory whenever required. Virtual memory is implemented using Demand Paging or
Demand Segmentation.
Demand Paging :
The process of loading the page into memory on demand (whenever page fault
occurs) is known as demand paging.
The process includes the following steps :

. If CPU try to refer a page that is currently not available in the main memory, it generates an interrupt indicating memory access fault.
2. The OS puts the interrupted process in a
blocking state. For the execution to proceed the OS must bring the required
page into the memory.
3. The OS will search for the required page in the
logical address space.
4. The required page will be brought from logical
address space to physical address space. The page replacement algorithms are
used for the decision making of replacing the page in physical address space.
5. The page table will updated accordingly.
6. The signal will be sent to the CPU to continue
the program execution and it will place the process back into ready state.
Hence whenever a page fault occurs these steps
are followed by the operating system and the required page is brought into
memory.
Advantages :
§ More processes may be maintained in the main
memory: Because we are going to load only some of the pages of any particular
process, there is room for more processes. This leads to more efficient
utilization of the processor because it is more likely that at least one of the
more numerous processes will be in the ready state at any particular time.
§ A process may be larger than all of main memory:
One of the most fundamental restrictions in programming is lifted. A process
larger than the main memory can be executed because of demand paging. The OS
itself loads pages of a process in main memory as required.
§ It allows greater multiprogramming levels by
using less of the available (primary) memory for each process.
Page Fault Service Time :
The time taken to service the page fault is called as page fault service time.
The page fault service time includes the time taken to perform all the above
six steps.
Let Main memory access time is: m
Page fault service time is: s
Page fault rate is : p
Then, Effective memory access time = (p*s) + (1-p)*m
Swapping:
Swapping a process out means removing all of its
pages from memory, or marking them so that they will be removed by the normal
page replacement process. Suspending a process ensures that it is not runnable
while it is swapped out. At some later time, the system swaps back the process
from the secondary storage to main memory. When a process is busy swapping
pages in and out then this situation is called thrashing.


At any given time, only few
pages of any process are in main memory and therefore more processes can be
maintained in memory. Furthermore time is saved because unused pages are not
swapped in and out of memory. However, the OS must be clever about how it
manages this scheme. In the steady state practically, all of main memory will
be occupied with process’s pages, so that the processor and OS has direct
access to as many processes as possible. Thus when the OS brings one page in,
it must throw another out. If it throws out a page just before it is used, then
it will just have to get that page again almost immediately. Too much of this
leads to a condition called Thrashing. The system spends most of its time
swapping pages rather than executing instructions. So a good page replacement
algorithm is required.
In the given diagram, initial degree of multi programming upto some extent of
point(lamda), the CPU utilization is very high and the system resources are
utilized 100%. But if we further increase the degree of multi programming the
CPU utilization will drastically fall down and the system will spent more time
only in the page replacement and the time taken to complete the execution of
the process will increase. This situation in the system is called as thrashing.
Causes of Thrashing :
1. High degree of multiprogramming : If the number of processes keeps on increasing
in the memory than number of frames allocated to each process will be
decreased. So, less number of frames will be available to each process. Due to
this, page fault will occur more frequently and more CPU time will be wasted in
just swapping in and out of pages and the utilization will keep on decreasing.
For example:
Let free frames = 400
Case 1: Number of process = 100
Then, each process will get 4 frames.
Case 2: Number of process = 400
Each process will get 1 frame.
Case 2 is a condition of thrashing, as the number of processes are
increased,frames per process are decreased. Hence CPU time will be consumed in
just swapping pages.
2. Lacks of Frames:If a process has less number of frames then
less pages of that process will be able to reside in memory and hence more
frequent swapping in and out will be required. This may lead to thrashing.
Hence sufficient amount of frames must be allocated to each process in order to
prevent thrashing.
Recovery of Thrashing :
§ Do not allow the system to go into thrashing by
instructing the long term scheduler not to bring the processes into memory
after the threshold.
§ If the system is already in thrashing then
instruct the midterm schedular to suspend some of the processes so that we can
recover the system from thrashing.
What is an INODE in Linux?
Information about files(data) are
sometimes called metadata. So you can even say it in another way, "An
inode is metadata of the data."
Whenever a user or a program needs
access to a file, the operating system first searches for the exact and unique
inode (inode number), in a table called as an inode table. In fact the program
or the user who needs access to a file, reaches the file with the help of the
inode number found from the inode table.
How does the structure of an inode
look like?
This is the most important part to
understand in terms of an inode. Here we will be discussing the contents of an
inode.
Inode
Structure of a Directory:
Inode structure of a directory just
consists of Name to Inode mapping of files and directories in that directory.
So here in the above shown diagram
you can see the first two entries of (.) and (..) dot dot. You might have seen
them whenever you list the contents of a directory.(most of the times they are
hidden. You will have to use -a option with "ls" command to see
them).
Why no file-name
in Inode information?
As pointed out earlier, there is no entry for file name in the Inode, rather the file name is kept as a separate entry parallel to Inode number. The reason for separating out file name from the other information related to same file is for maintaining hard-links to files. This means that once all the other information is separated out from the file name then we can have various file names which point to same Inode.
Q. Tier1 and Tier 2 hypervisor in virtual operating system
What is
Hypervisor?
A
Hypervisor also known as Virtual Machine Monitor (VMM) can be a piece of
software, firmware or hardware that gives an impression to the guest
machines(virtual machines) as if they were operating on a physical hardware. It
allows multiple operating system to share a single host and its hardware. The
hypervisor manages requests by virtual machines to access to the hardware
resources (RAM, CPU, NIC etc) acting as an independent machine.
Now the Hypervisor is mainly divided into two types namely
Type 1/Native/Bare Metal Hypervisor
Type 2/Hosted Hypervisor
Type 1
Hypervisor
·
This
is also known as Bare Metal or Embedded or Native Hypervisor.
·
It
works directly on the hardware of the host and can monitor operating systems
that run above the hypervisor.
·
It
is completely independent from the Operating System.
·
The
hypervisor is small as its main task is sharing and managing hardware resources
between different operating systems.
·
A
major advantage is that any problems in one virtual machine or guest operating
system do not affect the other guest operating systems running on the
hypervisor.

Examples:
VMware ESXi Server
Microsoft Hyper-V
Citrix/Xen Server
Type 2
Hypervisor
·
This
is also known as Hosted Hypervisor.
·
In
this case, the hypervisor is installed on an operating system and then supports
other operating systems above it.
·
It
is completely dependent on host Operating System for its operations
·
While
having a base operating system allows better specification of policies, any
problems in the base operating system a ffects the entire system as well even
if the hypervisor running above the base OS is secure.

Examples:
VMware Workstation
Microsoft Virtual PC
Oracle Virtual Box
Linux
Difference between Linux and Unix
|
Linux |
Unix |
|
It is an open-source operating system which
is freely available to everyone. |
It is an operating system which can be
only used by its copyrighters. |
|
It has different distros like Ubuntu, Redhat,
Fedora, etc |
IBM AIX, HP-UXand Sun Solaris. |
|
Nowadays, Linux is in great demand. Anyone can
use Linux whether a home user, developer or a student. |
It was developed mainly for servers,
workstations and mainframes. |
|
Linux supports more file system than Unix. |
It also supports file system but lesser than
Linux. |
|
Linux is just the kernel. |
Unix is a complete package of Operating
system. |
|
It provides higher security. Linux has about
60-100 viruses listed till date. |
Unix is also highly secured. It has about
85-120 viruses listed till date |
Linux Directories
What are Commands
A command is an
instruction given to our computer by us to do whatever we want. In Mac OS, and
Linux it is called terminal, whereas, in windows it is called command prompt.
Commands are always case sensitive.
Commands are
executed by typing in at the command line followed by pressing enter key.
This command
further passes to the shell which reads the command and execute it. Shell is a
method for the user to interact with the system. Default shell in Linux is
called bash (Bourne-Again Shell).
There are two types
of shell commands:
o Built-in shell commands: They
are part of a shell. Each shell has some built in commands.
o External/Linux commands: Each
external command is a separate executable program written in C or other
programming languages.
Linux Directory Commands
|
Directory
Comman |
Description |
|
The
pwd command stands for (print working directory). It displays the current
working location or directory of the user. It displays the whole working path
starting with /. It is a built-in command. |
|
|
The
ls command is used to show the list of a folder. It will list out all the
files in the directed folder. |
|
|
The
cd command stands for (change directory). It is used to change to the
directory you want to work from the present directory. |
|
|
With
mkdir command you can create your own directory. |
|
|
The
rmdir command is used to remove a directory from your system. |
Linux
pwd Command
Linux pwd (print
working directory) command displays your location currently you are working on.
It will give the whole path starting from the root ending to the directory.
Syntax:
1. pwd
Example:
Let's see an
example of pwd command.
Open your terminal
and type pwd, press enter key. You can see your directory path. Here, my path
is /home/sssit and my current location is sssit.
Notice here, that
loction will be shown from the root or from the filesystem.

Linux
cd Command
The "cd"
stands for 'change directory' and this command is used to change the current
directory i.e; the directory in which the user is currently working.
Syntax:
1. cd <dirname>
Example:
1. cd certs
It is the most
important and common command and will be used many times. With the help of this
command you can move all over your directories in your system. You can go to
your previous directory or previous to previous directory, or anywhere. Now
let's see how.
1)
Change from current directory to a new directory
In the snapshot,
first I have given pwd command, it brings me to the current directory, that is/home/sssit. Now I have given the command 'cd' to change my current directory
and have mentioned the path for the new directory /home/sssit/Desktop. Now as you can see I'm on my new directory that is
Desktop. And now my current working directory has changed toDesktop.
2)
Change directory using absolute path
In absolute path we
have to mention whole path starting from root.

In above example,
we want to change our directory to 'certs' from 'cups'. So we are providing the
whole path /run/cups/certs starting from the root (/). This is called absolute
path.
3)
Change directory using relative path

This exmple is same
as the above one. Only difference is that we are providing relative path. Look,
here also we have changed our directory from 'cups' to 'certs' but have not
mentioned the whole path. This is the relative path.
cd Options
|
option |
Description |
|
Brings
you to your home directory. |
|
|
Brings
you to your previous directory of the current directory. |
|
|
Brings
you to the parent directory of current directory. |
|
|
It
takes you to the entire system's root directory. |
|
|
It
will take you two directories up then move to dir1 and then finally to dir2. |
Linux
ls command
The ls is the list
command in Linux. It will show the full list or content of your directory. Just
type ls and press enter key. The whole content will be shown.
Example:
1. ls
Below, you can see,
after entering ls command, we got whole content list of /home/sssit directory.

Linux ls command options
|
ls option |
Description |
|
In
Linux, hidden files start with . (dot) symbol and they are not visible in the
regular directory. The (ls -a) command will enlist the whole list of the
current directory including the hidden files. |
|
|
It
will show the list in a long list format. |
|
|
ls
-lh |
This
command will show you the file sizes in human readable format. Size of the
file is very difficult to read when displayed in terms of byte. The (ls
-lh)command will give you the data in terms of Mb, Gb, Tb, etc. |
|
ls
-lhS |
If
you want to display your files in descending order (highest at the top)
according to their size, then you can use (ls -lhS) command. |
|
It
is used to display the files in a specific size format. Here, in [SIZE] you
can assign size according to your requirement. |
|
|
It
is used to display only sub directories. |
|
|
With
this you can exclude column of group information and owner. |
|
|
ls
-n |
It
is used to print group ID and owner ID instead of their names. |
|
This
command is used to print list as colored or discolored. |
|
|
ls
-li |
This
command prints the index number if file in the first column. |
|
ls
-p |
It
is used to identify the directory easily by marking the directories with a
slash (/) line sign. |
|
ls
-r |
It
is used to print the list in reverse order. |
|
ls
-R |
It
will display the content of the sub-directories also. |
|
ls
-lX |
It
will group the files with same extensions together in the list. |
|
ls
-lt |
It
will sort the list by displaying recently modified filed at top. |
|
It
gives the contents of home directory. |
|
|
It
give the contents of parent directory. |
|
|
ls
--version |
It
checks the version of ls command. |
Linux
mkdir | Linux Create Directory
Now let's learn how
to create your own directory with the help of command prompt.
The mkdir stands
for 'make directory'. With the help of mkdir command, you can create a new
directory wherever you want in your system. Just type "mkdir <dir name> , in place of <dir name> type the name of new
directory, you want to create and then press enter.
Syntax:
1. mkdir <dirname>
Example:
1. mkdir created

In above example, I
am in /home/sssit
directory. I have made a
directory 'created' by passing command "mkdir created".
Now if i'll try to
create a new file with the same file name 'created' that
technically already exists, I'll get an error message.
Note: If you will not provide a path then by default your
file will be created in your current directory only. If you want to create your
directory some where else, then provide the path of your destination directory
and your file will be created there.
To make multiple directories
Syntax:
1. mkdir <dirname1> <dirname2> <dirname3> ...

You can also create
multiple directories simultaneously. Look the example above, we have created
multiple directories 'file1
file2 file3' .
Mkdir Options
|
Options |
Description |
|
Add
directory including its sub directory. |
|
|
Print
a message for each created directory. |
|
|
Set
access privilege. |
Linux
rmdir Command
This command is
used to delete a directory. But will not be able to delete a directory
including a sub-directory. It means, a directory has to be empty to be deleted.
Syntax:
1. rmdir <dirname>
Example:
1. rmdir created
For example, in the
image below we have deleted directory 'file1' from 'envelope' successfully.
Now we want to delete 'created' directory. But it shows error as it contain 'file2'.
Hence, to delete 'created' directory, first we have to delete 'file2'. Then, we
will be able to delete 'created' directory.

rmdir -p
This command will
delete a directory including its sub-directories all at once. In below picture,
all sub-directories have been deleted with 'rmdir -p' command.

Linux
Files
In Linux system,
everything is a file and if it is not a file, it is a process. A file doesn't
include only text files, images and compiled programs but also include
partitions, hardware device drivers and directories. Linux consider everything
as as file.
Files are always
case sensitive. Let's understand it through an example.

In above example,
we have two files named as 'Demo.txt' and 'demo.txt'. Although, they both share
the same name but still they are two different files.
Types of Files:
1. Regular files (-): It
contain programs, executable files and text files.
2. Directory files (d): It
is shown in blue color. It contain list of files.
3. Special files
o Block file (b)
o Character device file (c)
o Named pipe file (p)
o Symbolic link file (l)
o Socket file (s)
Linux File Commands
|
Command |
Description |
|
Determines
file type. |
|
|
Used
to create a file. |
|
|
To
remove a file. |
|
|
To
copy a file. |
|
|
To
rename or to move a file. |
|
|
To
rename file. |
Linux
file command
file command is
used to determine the file type. It does not care about the extension used for
file. It simply uses file command and tell us the file type. It has several
options.
Syntax:
1. file <filename>
Example:
1. file 1.png

In above snapshot,
you can see file command along with different arguments, specifying their file
types.
Note: File command tell us the file type with the help of a
magic file that contains all the patterns to recognize a file type. Path of
magic file is /usr/share/file/magic. For more information enter the command
'man 5 magic'.
Linux File Command Options
|
Option |
Function |
|
Used
for special files. |
|
|
Used
to list types of all the files. |
|
|
Used
to list types of all the files from mentioned directory. |
|
|
It
will list out all the files starting from the alphabet present within the
given range. |
Linux
touch command
touch command is a
way to create empty files (there are some other mehtods also). You can update
the modification and access time of each file with the help of touch command.
Syntax:
1. touch <filename>
Example:
1. touch myfile1

Look above, we have
created two files namely 'myfile1' and 'myfile2' through touch command. To
create multiple files just type all the file names with a single touch command followed
by enter key. For example, if you would like to create 'myfile1' and 'myfile2'
simultaneously, then your command will be:
1. touch myfile1 myfile2
touch Options
|
Option |
Function |
|
To
change file access and modification time. |
|
|
It
is used to only modify time of a file. |
|
|
To
update time of one file with reference to the other file. |
|
|
To
create a file by specifying the time. |
|
|
It
does't create n empty file. |
Linux
rm | Linux Delete File
The 'rm' means
remove. This command is used to remove a file. The command line doesn't have a
recycle bin or trash unlike other GUI's to recover the files. Hence, be very
much careful while using this command. Once you have deleted a file, it is
removed permanently.
Syntax:
1. rm <filename>
Example:
1. rm myfile1

In above snapshot,
we have removed file myfile1 permanently with the help of 'rm' command.
rm Options
|
Option |
Description |
|
Used
to delete files having same extension. |
|
|
To
delete a directory recursively. |
|
|
Remove
a file interactively. |
|
|
Remove
a directory forcefully. |
Linux
cp | Linux Copy File
'cp' means copy.
'cp' command is used to copy a file or a directory.
To copy a file into
the same directory syntax will be,
1. cp <existing file name> <new file name>

In above snapshot,
we have created a copy of 'docu' and named it as 'newdocu'. If in
case, (in our case it is 'newdocu') alreade exists, then it will
simply over write the earlier file.
To copy a file in a different directory
We have to mention
the path of the destination directory.
In the snapshot
below, earlier there is no 'text' file. After giving the command, 'text' file
has been copied to the destination directory that is 'Desktop'.

cp Options
|
Option |
Function |
|
To
copy a directory along with its sub dirctories. |
|
|
To
copy multiple file or directories in a directory. |
|
|
To
backup the existing file before over writing it. |
|
|
Asks
for confirmtion. |
|
|
To
create hard link file. |
|
|
Preserves
attribute of a file. |
|
|
To
make sure source file is newer then destination file. |
Linux
mv | Linux Move File
Linux mv command is
used to move existing file or directory from one location to another. It is
also used to rename a file or directory. If you want to rename a single
directory or file then 'mv'option will be better to use.
How To Rename a File
While renaming a
file the inode number of both the files will remain the same.

In the above
example, we have renamed file 'docc' into 'document'. But inode number of both the files remains the same.
How To Rename a Directory
Directories can be
renamed in the same way as the files. In this case also inode number will
remain the same.

mv Option
|
Option |
Function |
|
Asks
for permission to over write. |
|
|
Move
multiple files to a specific directory. |
|
|
Used
to take backup before over writing. |
|
|
Only
move those files that doesn't exist. |
Linux
Rename File and Directory
To rename a file
there are other commands also like 'mv'. But 'rename' command is slightly advanced then others. This
command will be rarely used and it works differently on different distros of
linux. We'll work on Debian/Ubuntu examples.
Generally, renaming
is not a big task, but when you want to rename a large group of files at once
then it will be difficult to rename it with 'mv' command. In these cases, it is
adviced to use 'rename' command. It can convert upper case files to lower case
files and vice versa and cn overwrite files using perl expressions. This
command is a part of perl script.
Basic
syntax:
1. rename 's/old-name/new-name/' files
This
('s/old-name/new-name/') is the PCRE (perl compatible regular expression) which
denotes files to rename and how.
Linux
File Contents Command
There
are many commands which help to look at the contents of a file. Now we'll look
at some of the commands like head, tac, cat, less & more and strings.
We'll
discuss about the following file contents given in the table:
|
Commands |
Function |
|
It displays the beginning of
a file. |
|
|
It displays the last last
part of a file. |
|
|
This command is versatile and
multi worker. |
|
|
Opposite of cat. |
|
|
Command line diaplays
contents in pager form that is either in more format. |
|
|
Command line diaplays
contents in pager form that is either in less format. |
Linux
head command
The
'head' command displays the starting content of a file. By default, it displays
starting 10 lines of any file.
Syntax:
1. head <file name>
Example:
1. head jtp.txt
Linux
tail
The
'tail' command displays the last lines of a file. Its main purpose is to read
the error message.
By
default, it will also display the last ten lines of a file.
Syntax:
tail
<file name>
Example:
tail
jtp.txt

Look at
the above snapshot, last ten lines of the file 'jtp.txt' is
displayed with the help of command "tail
jtp.txt".
Some Question about LINUX
1) What is
Linux?
Linux is a UNIX
based operating system. Linus Torvalds first introduced it. It is an open
source operating system that was designed to provide free and a low-cost
operating system for the computer users.
2) What is the
difference between UNIX and Linux?
UNIX was
originally started as a propriety operating system for Bell Laboratories, which
later release their commercial version while Linux is a free, open source and a
non-propriety operating system for the mass uses.
3) What is Linux
Kernel?
Linux Kernel is
low-level system software. It is used to manage the hardware resources for the
users. It provides an interface for user-level interaction.
4) Is it legal
to edit Linux Kernel?
Yes. You can
edit Linux Kernel because it is released under General Public License (GPL) and
anyone can edit it. It comes under the category of free and open source
software.
5) What is LILO?
LILO is a boot
loader for Linux. It is used to load the Linux operating system into the main
memory to begin its operations.
6) What is the
advantage of open source?
Open source
facilitates you to distribute your software, including source codes freely to
anyone who is interested. So, you can add features and even debug and correct
errors of the source code.
7) What are the
basic components of Linux?
Just like other
operating systems, Linux has all components like kernel, shells, GUIs, system
utilities and application programs.
8) What is the
advantage of Linux?
Every aspect
comes with additional features, and it provides a free downloading facility for
all codes.
9) Define shell
It is an
interpreter in Linux.
10) Name some
shells that are commonly used in Linux.
The most
commonly used shells in Linux are bash, csh, ksh, bsh.
11) Name the
Linux which is specially designed by the Sun Microsystems.
Solaris is the
Linux of Sun Microsystems.
12) Name the
Linux loader.
LILO is the
Linux loader.
13) If you have
saved a file in Linux. Later you wish to rename that file, what command is
designed for it?
The 'mv' command
is used to rename a file.
14) Write about
an internal command.
The commands
which are built in the shells are called as the internal commands.
15) Define
inode.
Each file is
given a unique name by the operating system which is called as the inode.
16) If the
programmer wishes to execute an instruction at the specified time. Which
command is used?
The 'at' command
is used for the same.
17) Explain
process id.
The operating
system uniquely identifies each process by a unique id called as the process
id.
18) Name some
Linux variants.
Some of the
Linux commands are:
CentOS
Ubuntu
Redhat
Debian
Fedora
19) What is Swap
Space?
Swap space is
used to specify a space which is used by Linux to hold some concurrent running
program temporarily. It is used when RAM does not have enough space to hold all
programs that are executing.
20) What is
BASH?
BASH is a short
form of Bourne Again SHell. It was a replacement to the original Bourne shell,
written by Steve Bourne.
21) What is the
basic difference between BASH and DOS?
BASH commands
are case sensitive while DOS commands are not case sensitive.
DOS follows a
convention in naming files. In DOS, 8 character file name is followed by a dot
and 3 characters for the extension. BASH doesn't follow such convention.
22) What is a
root account?
The root account
is like a system administrator account. It provides you full control of the
system. You can create and maintain user accounts, assign different permission
for each account, etc.
23) What is CLI?
CLI stands for
Command Line Interface. It is an interface that allows users to type
declarative commands to instruct the computer to perform operations.
24) What is the
GUI?
GUI stands for
Graphical User Interface. It uses the images and the icons which are clicked by
the users to communicate with the system. It is more attractive and
user-friendly because of the use of the images and icons.
25) Which
popular office suite is available free for both Microsoft and Linux?
Open Office
Suite is available free for both Microsoft and Linux. You can install it on
both of them.
26) Suppose your
company is recently switched from Microsoft to Linux and you have some MS Word
document to save and work in Linux, what will you do?
Install Open Office
Suite on Linux. It facilitates you to work with Microsoft documents.
27) What is
SMTP?
SMTP stands for
Simple Mail Transfer Protocol. It is an internet standard for mail
transmission.
28) What is
Samba? Why is it used?
Samba service is
used to connect Linux machines to Microsoft network resources by providing
Microsoft SMB support.
29) What are the
basic commands for user management?
last,
chage,
chsh,
lsof,
chown,
chmod,
useradd,
userdel,
newusers etc.
30) What is the
maximum length for a filename in Linux?
255 characters.
31) Is Linux
Operating system virus free?
No, There is no
operating system till date that is virus free, but Linux is known to have less
number of viruses.
32) Which
partition stores the system configuration files in Linux system?
/stc partition.
33) Which
command is used to uncompress gzip files?
gunzip command
is used to uncompress gzip files.
34) Why do
developers use MD5 options on passwords?
MD5 is an
encryption method, so it is used to encrypt the passwords before saving.
35) What is a
virtual desktop?
The virtual
desktop is used as an alternative to minimizing and maximizing different
windows on the current desktop. Virtual desktop facilitates you to open one or
more programs on a clean slate rather than minimizing or restoring all the
needed programs.
36) What is the
difference between soft and hard mounting points?
In the soft
mount, if the client fails to connect the server, it gives an error report and
closes the connection whereas in the hard mount, if the client fails to access
the server, the connection hangs; and once the system is up, it again accesses
the server.
37) Does the
Alt+Ctrl+Del key combination work in Linux?
Yes, it works
like windows.
38) What are the
file permissions in Linux?
There are 3
types of permissions in Linux OS that are given below:
Read: User can
read the file and list the directory.
Write: User can
write new files in the directory .
Execute: User
can access and run the file in a directory.
39) What are the
modes used in VI editor?
There are 3
types of modes in vi Editor:
Regular mode or
command mode
Insertion mode
or edit mode
Replacement mode
or Ex-mode
40) How to exit
from vi editors?
The following
commands are used to exit from vi editors.
:wq saves the
current work and exits the VI.
:q! exits the VI
without saving current work.
41) How to
delete information from a file in vi?
The following
commands are used to delete information from vi editors.
x deletes a
current character.
dd deletes the
current line.
42) How to
create a new file or modify an existing file in vi?
vi filename
Linux file command to give authentication of read only and read
/ write as well as exclusive [BPDB-2018]
chmod is
used to change the permissions of files or directories.
Overview
On Linux and other Unix-like operating
systems, there is a set of rules for
each file which defines who can access that file, and how they can access it.
These rules are called file permissions or file modes. The command
name chmod stands for "change mode", and it is used
to define the way a file can be accessed.
Before continuing, you should read the
section What Are File Permissions, And How Do They Work? in our documentation of the umask command. It contains a comprehensive description of
how to define and express file permissions.
In general, chmod commands
take the form:
chmod optionspermissionsfile nameIf no options are
specified, chmod modifies the permissions of the file
specified by file name to the permissions specified by permissions.
permissions defines the permissions for the owner of the file
(the "user"), members of the group who owns the file (the
"group"), and anyone else ("others"). There are two ways to
represent these permissions: with symbols (alphanumeric characters), or
with octal numbers (the
digits 0 through 7).
Let's say you are the owner of a file
named myfile, and you want to set its permissions so that:
1.
the user can read, write,
ande xecute it;
2.
members of your group can read
ande xecute it; and
3.
others may
only read it.
This command will do the trick:
chmod u=rwx,g=rx,o=r myfile
This
example uses symbolic permissions notation. The letters u, g,
and o stand for "user", "group",
and "other". The equals sign ("=") means
"set the permissions exactly like this," and the letters "r",
"w", and "x" stand for "read",
"write", and "execute", respectively. The commas separate the different classes of
permissions, and there are no spaces in between them.
Here is the equivalent command using octal
permissions notation:
chmod 754 myfileHere the digits 7, 5,
and 4 each individually represent the permissions for the
user, group, and others, in that order. Each
digit is a combination of the numbers 4, 2, 1,
and 0:
·
4 stands for
"read",
·
2 stands for
"write",
·
1 stands for
"execute", and
·
0 stands for
"no permission."
So 7 is the combination of
permissions 4+2+1 (read, write, and
execute), 5 is 4+0+1(read, no write,
and execute), and 4 is 4+0+0 (read,
no write, and no execute).
Syntax
chmod [OPTION]... MODE[,MODE]... FILE...chmod [OPTION]... OCTAL-MODEFILE...chmod [OPTION]... --reference=RFILE FILE...Options
|
-c, --changes |
Like --verbose, but gives verbose output only when a
change is actually made. |
|
-f, --silent, --quiet |
Quiet mode; suppress most error messages. |
|
-v, --verbose |
Verbose mode; output a diagnostic message for every file processed. |
|
--no-preserve-root |
Do not treat '/' (the root directory) in any special way, which is the
default setting. |
|
--preserve-root |
Do not operate recursively on '/'. |
|
--reference=RFILE |
Set permissions to match those of file RFILE, ignoring
any specified MODE. |
|
-R, --recursive |
Change files and directories recursively. |
|
--help |
Display a help message and exit. |
|
--version |
Output version information
and exit. |
Technical Description
chmod changes
the file mode of each specified FILE according to MODE,
which can be either a symbolic representation of changes to make, or an octal number representing the bit pattern for the new
mode bits.
The format of a symbolic mode is:
[ugoa...][[+-=][perms...]...]
where perms is either zero
or more letters from the set r, w, x, X, s and t,
or a single letter from the set u, g, and o.
Multiple symbolic modes can be given, separated by commas.
A numeric mode is from one to four octal
digits (0-7), derived by adding up the bits with values 4, 2,
and 1. Omitted digits are assumed to be leading zeros. The first
digit selects the set user
ID (4) and set group ID (2)
and restricted deletion or sticky (1) attributes. The second digit
selects permissions for the user who owns the read (4), write (2),
and execute (1); the third selects permissions for other users in the
file's group, with the same values; and the fourth for other users not in the
file's group, with the same values.
chmod never
changes the permissions of symbolic links; the chmod system
call cannot change their permissions. However, this is not a problem since the
permissions of symbolic links are never used. However, for each symbolic link listed
on the command line, chmod changes
the permissions of the pointed-to file. In contrast, chmod ignores
symbolic links encountered during recursive directory
traversals.
Setuid And Setgid Bits
chmod clears
the set-group-ID bit of a regular file if the file's group ID does not match
the user's effective group ID or one of the user's supplementary group IDs,
unless the user has appropriate privileges. Additional restrictions may cause
the set-user-ID and
set-group-ID bits of MODE or RFILE to be
ignored. This behavior depends on the policy and functionality of the
underlying chmod system call. When in doubt, check the
underlying system behavior.
chmod preserves
a directory's set-user-ID and set-group-ID bits unless you explicitly specify
otherwise. You can set or clear the bits with symbolic modes like u+s and g-s,
and you can set (but not clear) the bits with a numeric mode.
Restricted Deletion Flag (or "Sticky
Bit")
The restricted deletion flag or sticky bit
is a single bit, whose interpretation depends on the file type. For
directories, it prevents unprivileged users from removing or renaming a file in
the directory unless they own the file or the directory; this is called the
restricted deletion flag for the directory, and is commonly found on
world-writable directories like /tmp. For regular files on some
older systems, the bit saves the program's text image on the swap device so it
will load more quickly when run; this is called the sticky bit.
Viewing Permissions of files
A quick and easy way to list a file's
permissions are with the long listing (-l) option of the ls command. For example, to view the permissions
of file.txt, you could use the command:
ls -l file.txt...which will display output that looks like
the following:
-rwxrw-r-- 1 hope hopestaff 123 Feb 03 15:36 file.txt
Here's what each part of this information
means:
|
- |
The first character represents the file type: "-"
for a regular file, "d" for a directory, "l"
for a symbolic link. |
|
rwx |
The next three characters represent the permissions for the file's
owner: in this case, the owner may read from, write
to, ore xecute the file. |
|
rw- |
The next three characters represent the permissions for members of
the file group. In this case, any member of the file's owning group may read
from or write to the file. The final dash is a placeholder; group
members do not have permission to execute this file. |
|
r-- |
The permissions for "others" (everyone else). Others may
only read this file. |
|
1 |
The number of hard links to this
file. |
|
hope |
The file's owner. |
|
hopestaff |
The group to whom the file belongs. |
|
123 |
The size of the file in blocks. |
|
Feb 03 15:36 |
The file's mtime (date and time when the file was last modified). |
|
file.txt |
The name of the file. |
Examples
chmod 644 file.htmSet the permissions of file.htm to
"owner can read and write; group can read only; others can read
only".
chmod -R 755 myfilesRecursively (-R) Change the
permissions of the directory myfiles, and all folders and files it
contains, to mode 755: User can read, write, and execute; group
members and other users can read and execute, but cannot write.
chmod u=rw example.jpgChange the permissions for the owner of example.jpg so
that the owner may read and write the file. Do not change the permissions for
the group, or for others.
chmod u+s comphope.txtSet the "Set-User-ID" bit of comphope.txt,
so that anyone who attempts to access that file does so as if they are the
owner of the file.
chmod u-s comphope.txtThe opposite of the above command; un-sets
the SUID bit.
chmod 755 file.cgi

Set the permissions of file.cgi to
"read, write, and execute by owner" and "read and execute by the
group and everyone else".
chmod 666 file.txtSet the permission of file.txt to
"read and write by everyone.".
chmod a=rw file.txtAccomplishes the same thing as the above
command, using symbolic notation.
Tutorial point- https://www.tutorialspoint.com/
Java T point- https://www.javatpoint.com/
Geeksforgeeks- https://www.geeksforgeeks.org
Techopedia - https://www.techopedia.com/
guru99- https://www.guru99.com/
techterms - https://techterms.com/
webopedia - https://www.webopedia.com/
study - https://study.com/
wikipedia - https://en.wikipedia.org/\
cprogramming - https://www.cprogramming.com/
w3schools - https://www.w3schools.com
Electronic hub- https://www.electronicshub.org







{kind=link}
{kind=link}
0 মন্তব্যসমূহ